
接上一篇... 见:
- Group
为了方便我还是把我的表结构贴上来:
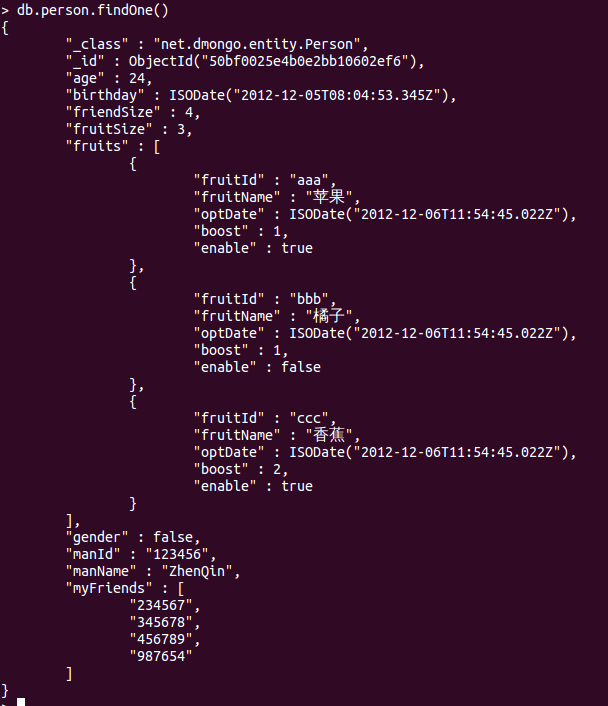
和数据库一样group常常用于统计。MongoDB的group还有很多限制,如:返回结果集不能超过16M, group操作不会处理超过10000个唯一键,好像还不能利用索引[不很确定]。
Group大约需要一下几个参数。
- key:用来分组文档的字段。和keyf两者必须有一个
- keyf:可以接受一个javascript函数。用来动态的确定分组文档的字段。和key两者必须有一个
- initial:reduce中使用变量的初始化
- reduce:执行的reduce函数。函数需要返回值。
- cond:执行过滤的条件。
- finallize:在reduce执行完成,结果集返回之前对结果集最终执行的函数。可选的
下面我用Java对他们做一些测试。
我们以age年龄统计集合中存在的用户。Spring Schema和上次的一样。有了MongoTemplate对象我们可以做所有事的。以age统计用户测试代码如:
@Test public void testGroupBy() throws Exception { String reduce = "function(doc, aggr){" + " aggr.count += 1;" + " }"; Query query = Query.query(Criteria.where("age").exists(true)); DBObject result = mongoTemplate.getCollection("person").group(new BasicDBObject("age", 1), query.getQueryObject(), new BasicDBObject("count", 0), reduce); Map map = result.toMap(); System.out.println(map); for (Map.Entry o : map.entrySet()) { System.out.println(o.getKey() + " " + o.getValue()); } } key为new BasicDBObject("age", 1)
cond为:Criteria.where("age").exists(true)。即用户中存在age字段的。
initial为:new BasicDBObject("count", 0),即初始化reduce中人的个数为count为0。假如我们想在查询的时候给每个年龄的人增加10个假用户。我们只需要传入BasicDBObject("count", 10).
reduce为:reduce的javascript函数
上面的执行输出如:
2 [age:23.0, count:1.0]1 [age:25.0, count:1.0]0 [age:24.0, count:1.0]
前面的是一个序号,是Mongo的java-driver加上去的。我们可以看到结果在后面。
不过你可能都觉得reduce这段代码用Java写的太繁琐了,要是和Python一样支持多行字符串多好啊。 我也烦。下面的例子我用Groovy写,不过我尽量写的贴近Java。
同样的reduce,用Groovy只需这样:
def reduce = """ function(doc, aggr){ aggr.count += 1; } """; 用age统计用户这是基本的需求了。下面我来几个高级点的。
我的表结构中用户的朋友[myFriends]是一个数组类型的,mongo提供的查询中对数组查询时数组长度$size只能用来判断,却不能用来输出[至少我没找到]。那么我们用group操作来统计一下每个人有几个朋友。测试代码如:
@Test void testFriendGroupUserFriendCount() throws Exception { def reduce = """ function(doc, aggr){ aggr.manId = doc.manId; doc.myFriends.forEach(function(z){ aggr.count += 1; }) } """; Query query = Query.query(Criteria.where("myFriends").exists(true)); DBObject result = mongoTemplate.getCollection("person").group( new BasicDBObject("manId", 1), query.getQueryObject(), new BasicDBObject("count", 0), reduce); Map map = result.toMap(); for (Map.Entry o : map.entrySet()) { System.out.println(o.getKey() + " ==> " + o.getValue()); } } 执行结果如:
2 ==> [manId:345678, count:2.0]1 ==> [manId:234567, count:2.0]0 ==> [manId:123456, count:4.0]
上面的reduce中遍历文档的数组用了forEach,我记得好像Javascript中不能这么做吧? 我对js不熟,希望牛人解答下。
上面的例子一直都没用到finallize,下面的测试我希望能用上。
我们统计每个人最喜欢水果是哪个?每个人都有n个自己的喜欢的水果,fruits.boost是每个水果的权重。那么我们找出最喜欢的那个?
测试代码:
@Test void testGroupByFruitFinallize() throws Exception { def reduce = """ function(doc, out) { out.name = doc.manName; for(i in doc.fruits) { if(doc.fruits[i] in out.fruits) { out.fruits[doc.fruits[i].fruitId]++; } else { out.fruits[doc.fruits[i].fruitId] = 1; } } } """; def finallizer = """ function(out) { var mostPopular = 0; for(i in out.fruits) { if(out.fruits[i] > mostPopular) { out.fruitId = i; mostPopular = out.fruits[i]; } } delete out.fruits; return out; } """; Query query = new BasicQuery("{}"); long time = System.currentTimeMillis(); DBObject result = mongoTemplate.getCollection("person").group(new BasicDBObject("fruits", true), query.getQueryObject(), new BasicDBObject("fruits", new BasicDBObject()), reduce, finallizer); System.out.println("use time: " + (System.currentTimeMillis() - time)); Map map = result.toMap(); for (Map.Entry o : map.entrySet()) { System.out.println(o.getKey() + " " + o.getValue()); } } 它的测试输出为:
2 [name:ZhenZi, fruitId:www]1 [name:YangYan, fruitId:www]0 [name:ZhenQin, fruitId:aaa]
OK,他完成了。
关于keyf我找了很多资料,目前还没发现怎么使用。希望有人能解答下。